
티스토리 뷰
💡 최상용님의 실습으로 배우는 선착순 이벤트 시스템 강의를 듣고 정리한 내용입니다.
목차
글 목록
- [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (1/3) - 동시성 이슈와 Redis로 해결하기
- [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (2/3) - Kafka로 시스템 안정성 향상하기
- [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (3/3) - 요구사항 변경과 쿠폰 발급 실패 예외처리
- [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (번외) - DLT(DeadLetterTopic)을 이용한 메시지 Consume 재처리
배경
지난 [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (1/3) - 동시성 이슈와 Redis로 해결하기 글에서 가장 기본적인 선착순 이벤트 시스템을 구현하고, 구현 중 발생한 동시성 이슈(쿠폰이 정해진 개수보다 더 많이 발급)를 Redis로 해결해하였다.
K6로 시스템 성능 테스트까지 진행하였는데, 이번에는 Kafka를 도입하여 시스템 안정성을 향상하고 가용성을 높인다.
작업환경 세팅
Kafka를 관리하는 중앙 집중형 서비스 Zookeeper와 Kafka를 Docker Compose를 통해 설치하였다. Zookeeper는 브로커 메타데이터 관리, 파티션 리더 선출, 토픽과 파티션 구성 등의 카프카 운영에 필요한 조정 서비스를 제공하는 역할을 한다. (과거에는 오프셋 저장도 Zookeeper가 담당했다. 현재는 Kafka가 오프셋을 내부의 특별한 토픽에 저장한다.)
최근에는 Kafka와 Zookeeper 간의 강한 의존성으로 인해, Kafka를 독립적으로 관리하고 Zookeeper에 대한 의존성을 제거하는 방향으로 발전하고 있으나, 예시에서는 간단한 진행을 위해 Zookeeper와 Kafka를 함께 설치하였다.
다음과 같이 docker-compose.yml 파일을 작성한다.
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
작성한 docker-compose.yml 파일을 통해 도커 컨테이너를 실행한다. (-d 옵션을 주어 데몬으로 실행하였다.)
# yml 파일 내용 확인
cat docker-compose.yml
# kafka, zookeeper 컨테이너 실행
docker-compose up -d
Kafka 간략히 알아보기
기존에 작성한 쿠폰 발급 프로젝트에 Kafka를 도입하기에 앞서, 아주 간략한 Kafka의 구조를 알아본다.
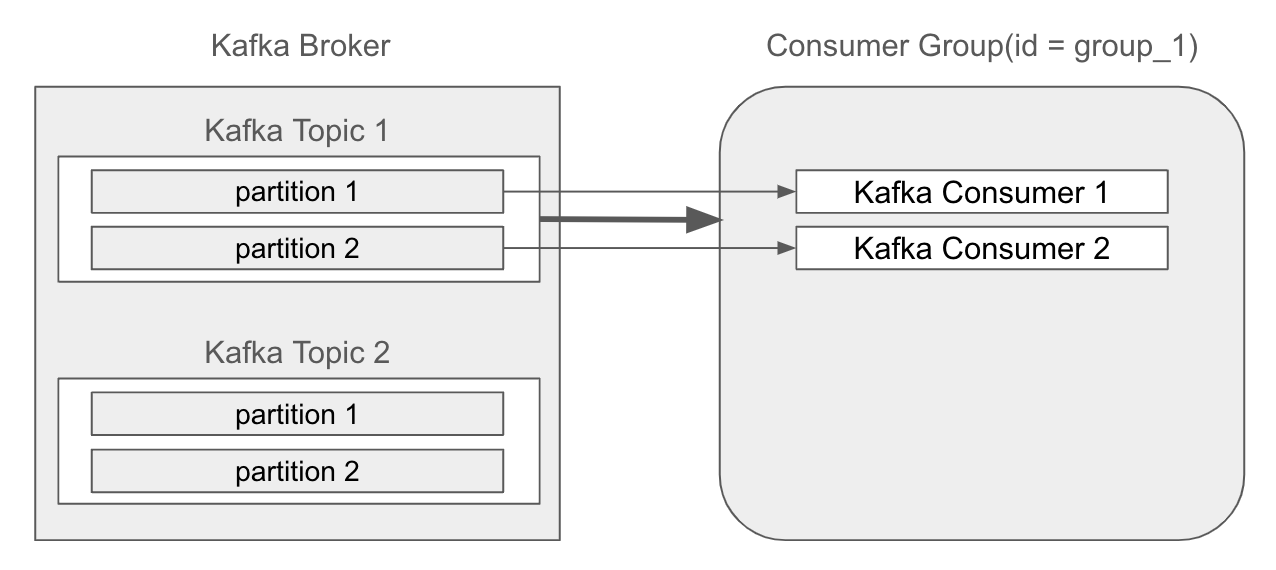
카프카(Kafka)는 소스에서 목적지까지 이벤트를 실시간 스트리밍을 제공하는 분산 이벤트 스트리밍 플랫폼이다. 아주 대략적인 카프카의 구조는 다음과 같다. 토픽(Topic)은 메시지를 담고 있는 큐(Queue) 역할을 한다. 프로듀서(Producer)가 토픽에 데이터를 삽입하는 출발지(Source) 역할을하고, 컨슈머(Consumer)가 토픽에 삽입된 데이터를 꺼내어 처리하는 목적지(Destination) 역할을 한다.

대용량 데이터 처리가 필요한 경우 일반적으로 토픽을 파티셔닝하여 처리량을 늘리는데, 이 경우 카프카 토픽과 프로듀서, 컨슈머는 다음과 같이 구성한다.
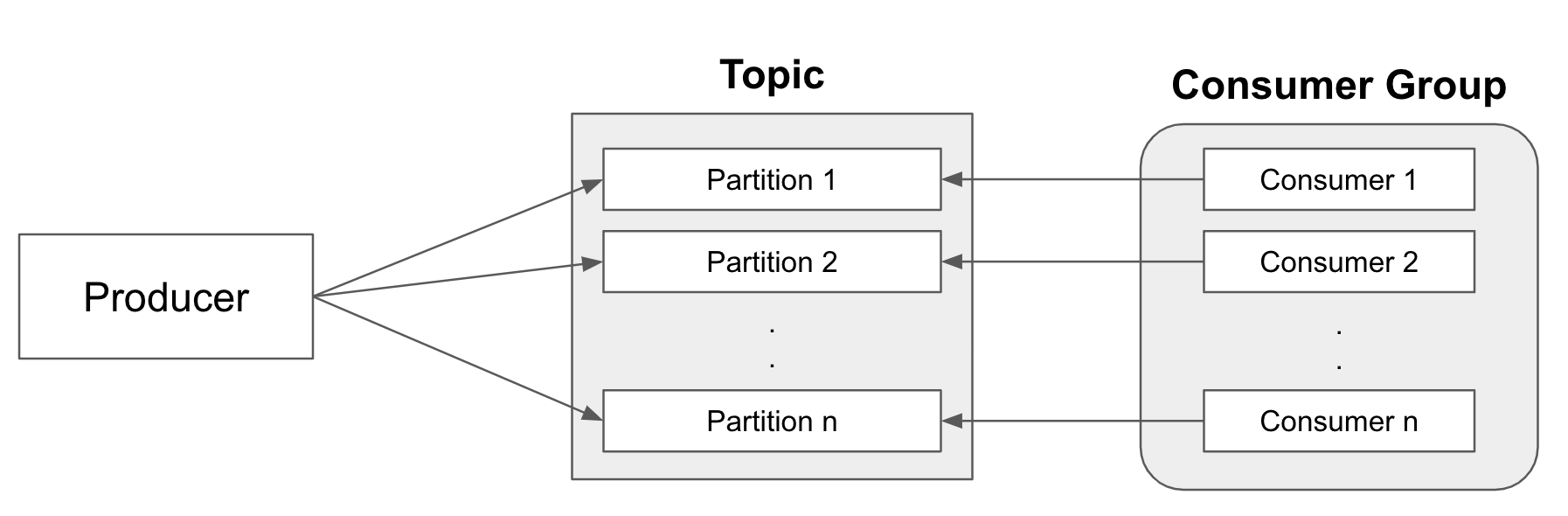
Producer (프로듀서)가 토픽에 메시지를 발행하며, 각 메시지는 특정 파티션으로 보내진다. 이때 데이터 처리량 향상을 위해 Topic (토픽)은 여러 개의 파티션으로 구성되는데(파티셔닝), 프로듀서가 메시지를 보낼 때 메시지는 특정 파티션에 기록된다.
동일한 토픽을 바라보는 여러개의 Consuemr가 Consumer Group (컨슈머 그룹)을 구성한다. 컨슈머 그룹 안에 있는 여러 컨슈머들이 각 파티션에 대응하여 메시지를 읽고 처리한다. 일반적으로 한 파티션의 데이터는 한 컨슈머만 읽도록 할당되며, 동일한 컨슈머 그룹 내의 다른 컨슈머는 다른 파티션의 데이터를 읽어서 처리한다.
Producer 사용하기
기본적인 카프카의 구조를 살펴보았으니, 쿠폰 시스템에 적용하여 Kafka를 활용하여 쿠폰을 생성하도록 변경해보자.
build.gradle에 카프카 관련 dependency를 추가한다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.kafka:spring-kafka'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.mysql:mysql-connector-j'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
dependency를 추가하고나서 gradle을 reload하면 다음과 같이 External Libararies에 다음과 같이 spring-kafka 관련 라이브러리가 추가된 것을 볼 수 있다.

KafkaProducerConfig
Producer 인스턴스를 생성하는데 필요한 설정값을 작성한다. 스프링 카프카는 ProducerFactory를 제공하고 있어 손쉽게 설정값을 입력할 수 있다. KafkaProducerConfig은 다음과 같이 두 개의 빈을 등록하는데 각각 그 역할은 다음과 같다.
- producerFactory : kafkaTemplate에서 템플릿을 작성할때 프로듀서 설정값을 입력
- kafkaTemplate : 프로듀서(Producer)가 카프카 토픽에 메시지를 발행하는데 사용할 카프카 템플릿
producerFactory에는 카프카 서버 정보, 메시지 key와 value의 serializer 정보 등을 지정한다. 예시에서는 다음과 같은 값을 입력하였다.
- ProducerConfig.BOOTSTRAP_SERVERS_CONFIG : 카프카 브로커의 주소
- ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG : 메시지 key의 직렬화 방식
- ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG : 메시지 value의 직렬화 방식
package org.example.api.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.LongSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Long> producerFactory() {
// ProducerFactory<String, Long> : key는 Sring, value는 Long으로 지정한다.
// 설정 값을 담아줄 map을 변수로 선언한다.
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 메시지 키로 “user123” 과 같은 문자열을 사용한다.
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 메시지 값으로 1L, 2L, 3L과 같은 Long 타입을 사용한다.
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, LongSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, Long> kafkaTemplate() {
// 카프카 템플릿을 작성할때 위에서 작성한 설정값을 담아준다.
// 프로듀서(Producer)는 이 카프카 템플릿을 사용해서 토픽에 메시지를 발행한다.
return new KafkaTemplate<>(producerFactory());
}
}
CouponCreateProducer
앞서 작성한 프로듀서 설정 클래스 KafkaProducerConfig의 kafkaTemplate 빈을 사용해서 토픽에 메시지를 발행할 프로듀서(Producer)를 구현한다.
package org.example.api.producer;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Component
@RequiredArgsConstructor
public class CouponCreateProducer {
private static final String TOPIC_NAME = "coupon-create";
private final KafkaTemplate<String, Long> kafkaTemplate;
public void create(Long userId) {
// 카프카 템플릿을 사용해서 coupon-create 토픽에 userId를 전송한다. (메시지 발행)
kafkaTemplate.send(TOPIC_NAME, userId);
log.info("메시지 발행 성공, topicName : {}, userId : {}", TOPIC_NAME, userId);
}
}
ApplyService
앞서 구현한 CouponCreateProducer 의존관계를 추가하고, 쿠폰 발급을 실제 데이터베이스에 하는 것이 아니라 카프카 토픽에 userId 를 메시지로 발행하도록 수정한다.
package org.example.api.service;
import org.example.api.domain.Coupon;
import org.example.api.producer.CouponCreateProducer;
import org.example.api.repository.CouponCountRepository;
import org.example.api.repository.CouponRepository;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
@Service
@RequiredArgsConstructor
// 쿠폰에 대한 CRUD를 통해 비즈니스 로직을 제공
public class ApplyService {
private final CouponRepository couponRepository;
private final CouponCountRepository couponCountRepository;
private final CouponCreateProducer couponCreateProducer;
// 쿠폰 발급 로직
public void apply(Long userId) {
// 쿠폰 개수 조회(mysql)
// long count = couponRepository.count();
// 쿠폰 개수 조회 로직을 레디스의 incr 명령어를 호출하도록 변경한다.
// 즉 쿠폰 발급 전에 발급된 쿠폰의 개수를 1 증가하고 그 개수를 확인한다.
Long increment = couponCountRepository.increment();
// 쿠폰의 개수가 발급 가능한 개수보다 많은 경우 -> 발급 불가
if(increment > 100) {
return;
}
// 발급이 가능한 경우 -> 쿠폰 새로 생성(발급)
// couponRepository.save(new Coupon(userId)); // 쿠폰 발급(mysql)
// 쿠폰을 직접 DB에 생성하지 않고 카프카 토픽에 userId를 전송한다.
couponCreateProducer.create(userId);
}
}
카프카 토픽 생성과 Producer 테스트
CouponCreateProducer에서 메시지를 발급할 coupon-create 토픽을 생성한다. 도커 컨테이너에서 카프카 서버를 실행하고 있으므로 다음과 같이 docker exec 명령어로 생성한다.
docker exec -it kafka kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic coupon-create
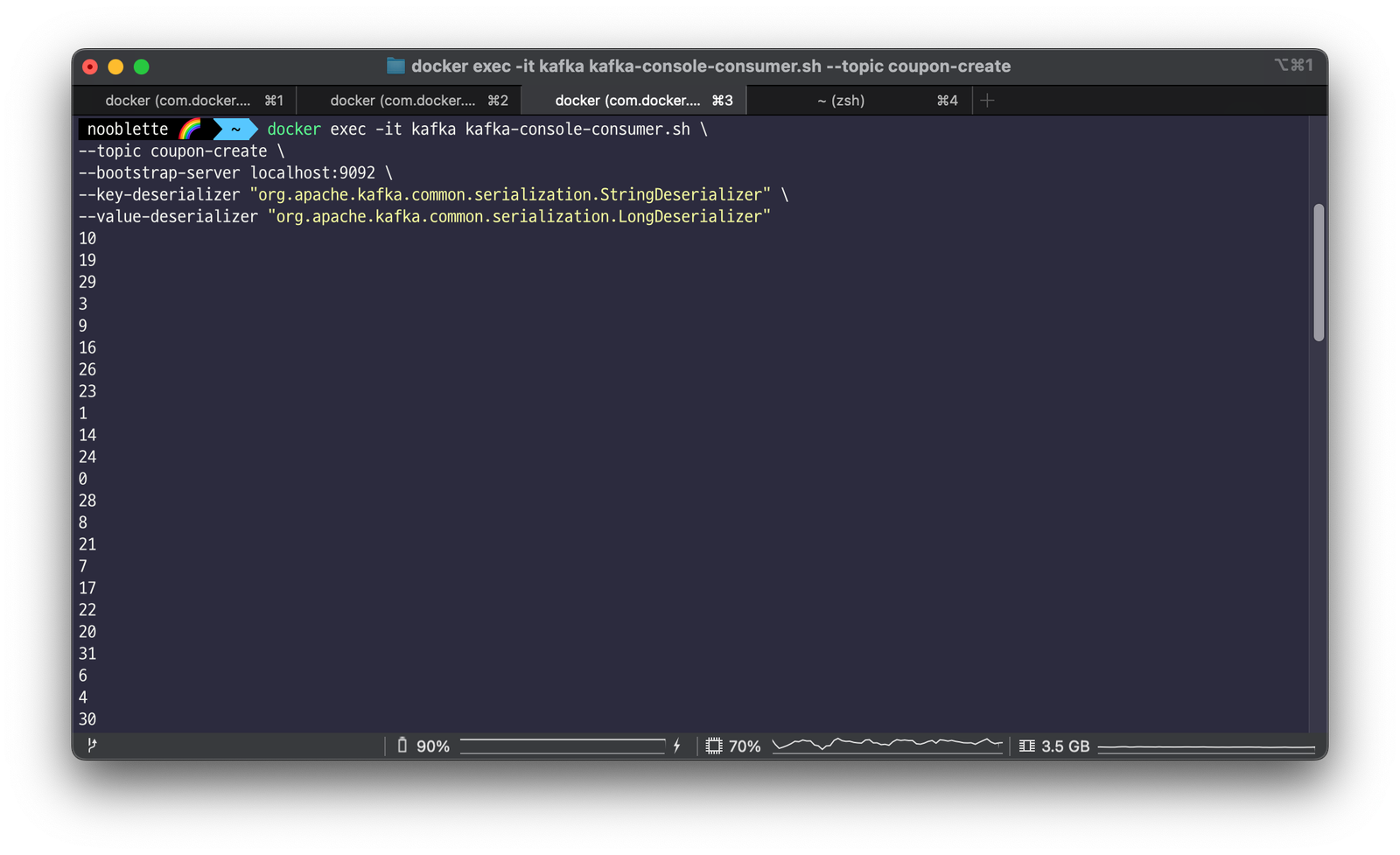
컨슈머를 구현하기에 앞서 임시로 메시지 발행이 잘 되는지 테스트해보자. 토픽 생성 명령과 Conusmer 실행 정보는 다음과 같다. 프로듀서와 동일한 타입으로 key와 value를 Deserializer한다.
docker exec -it kafka kafka-console-consumer.sh \
--topic coupon-create \
--bootstrap-server localhost:9092 \
--key-deserializer "org.apache.kafka.common.serialization.StringDeserializer" \
--value-deserializer "org.apache.kafka.common.serialization.LongDeserializer"
Consumer를 실행하고 나서 ApplyServiceTest의 여러명응모() 테스트 코드를 실행한다.

컨슈머에서 토픽에 발행된 userId 값들을 출력하는 것을 확인할 수 있다.
Consumer 구현하기
Producer가 copuon-create 토픽에 메시지를 정상 발행하는 것을 확인하였으니, Consumer 설정을 추가하고 Consumer를 구현한다. (이때 Consumer는 기존 프로젝트에 별도 모듈로 구성하였다.)
Consumer를 별도 모듈로 구성하였으니 build.gralde에 라이브러리를 추가해준다.
카프카 컨슈머를 구현할 모듈이므로 Spring for Apache Kafka를 추가하고, 컨슈머에서 데이터를 받아와 처리해야하므로(= 데이터베이스에 적재) MySQL Driver와 Spring Data JPA를 추가해준다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.kafka:spring-kafka'
runtimeOnly 'com.mysql:mysql-connector-j'
compileOnly 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.kafka:spring-kafka-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
KafkaConsumerConfig
스프링 카프카를 사용하면 KafkaConsumerConfig를 통해 간단하게 Kafka Consumer 인스턴스의 설정 정보와 토픽으로부터 메시지를 수신해올 KafkaListenr가 동작할 환경을 정의할 수 있다. 이때 consumerFactory와 kafkaListenerContainerFactory 빈을 등록하는데 그 역할은 다음과 같다.
ConsumerFactory
카프카 Consumer 인스턴스를 생성하는데 필요한 정보를 세팅하고 이 정보를 기반으로 인스턴스를 생성한다. Kafka Consumer의 구성 정보를 포함하여, Kafka 서버와의 연결 및 메시지의 역직렬화 등을 설정한다. 예시에서는 다음 정보를 세팅하였다.
- 카프카 브로커 서버의 IP와 Port
- 컨슈머가 속하는 Group Id
- Key의 역직렬화 방식(Deserializer class)
- Value의 역직렬화 방식(Deserializer class)
kafkaListenerContainerFactory
KafkaListener가 동작할 환경(= kafkaListenerContainer)를 생성한다. 이 팩토리 클래스가 생성하는 컨테이너로는 KafkaMessageListenerContainer 또는 ConcurrentMessageListenerContainer 등이 있으며 두 컨테이너의 차이는 병렬처리여부이다.
- KafkaMessageListenerContainer : 싱글 스레드에서 설정 토픽 또는 파티션의 모든 메세지를 수신한다.
- ConcurrentMessageListenerContainer : 하나 이상의 KafkaMessageListenerContainer 인스턴스를 제공하여 멀티스레드 환경에서 메시지를 병렬로 처리할 수 있다.
- 아래 예시에서는 ConcurrentMessageListenerContainer로 리스너 컨테이너를 생성하였다.
package org.example.consumer.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
@Configuration
public class KafkaConsumerConfig {
// Consumer 인스턴스를 생성하는데 필요한 설정값들을 정의
// 컨슈머 설정 정보를 세팅하는 ConsumerFactory 빈 등록
@Bean
public ConsumerFactory<String, Long> consumerFactory() {
// 컨슈머 설정 값들을 담을 Map 선언
Map<String, Object> config = new HashMap<>();
// 컨슈머 설정 정보 세팅
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // 서버 정보
config.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1"); // 컨슈머 그룹 ID
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // key 역직렬화 클래스
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); // value 역직렬화 클래스
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Long> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Long> factory = new ConcurrentKafkaListenerContainerFactory<>();
// 앞서 세팅한 설정 값을 담는 consuemerFactory를 설정해준다.
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
CouponCreatedConsumer
다음으로는 메시지를 수신하고 쿠폰을 발급할(비즈니스 로직)을 담는 Consumer를 구현한다. @KafkaListener 어노테이션을 두어 메시지를 받아올 대상 토픽명과 이 컨슈머가 속할 컨슈머 그룹 ID, Kafka Listener가 동작할 Container의 Factory 빈을 지정한다.
스프링 카프카를 사용한다면, 스프링이 Application Context(스프링 컨테이너)를 초기화할 때, KafkaListenerContainerFactory와 ConsumerFactory도 빈으로 등록하며, 이 @KafkaListener 어노테이션이 붙은 클래스를 빈으로 등록한다.
즉, 빈 생성과 의존관계 주입 시점에 @KafkaListener 어노테이션을 보고 (KafkaConsumerConfig에서 작성한 kafkaListenerContainerFactory 빈에 의해) 해당 리스너가 동작할 KafkaListenerContainer 인스턴스를 생성한다. 또한 kafkaListenerContainerFactory는 ConsumerFactory 빈을 사용하여 생성된 Consumer 인스턴스를 기반으로 KafkaListenerContainer를 생성한다.
package org.example.consumer.consumer;
import org.example.consumer.domain.Coupon;
import org.example.consumer.repository.CouponRepository;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class CouponCreatedConsumer {
private final CouponRepository couponRepository;
public CouponCreatedConsumer(CouponRepository couponRepository) {
this.couponRepository = couponRepository;
}
@KafkaListener(
topics = "coupon-create", // 토픽 명 지정
groupId = "group_1", // 컨슈머 그룹 ID 지정
containerFactory = "kafkaListenerContainerFactory" // Listener Container Factory 지정
)
public void listener(Long userId) {
couponRepository.save(new Coupon(userId));
}
}
메시지 발행(Produce)와 Consume 흐름
로직을 잘 작성했는지 테스트하기에 앞서 Kafka를 도입하고 난 후 데이터 흐름을 되짚어본다. 다음과 같이 프로듀서가 토픽에 메시지를 발행했다고 가정한다. 프로듀서가 발행한 메시지는 브로커가 수신하여 토픽의 파티션에 저장한다. (기본적으로 발행할 토픽은 지정할 수 있지만 어떤 파티션으로 발행될지는 개발자가 알 수 없다, 프로듀서의 설정과 시스템의 파티션 할당 정책에 따라 달라진다. 만일 제어가 필요하다면 파티션 번호를 지정할 수는 있다.)
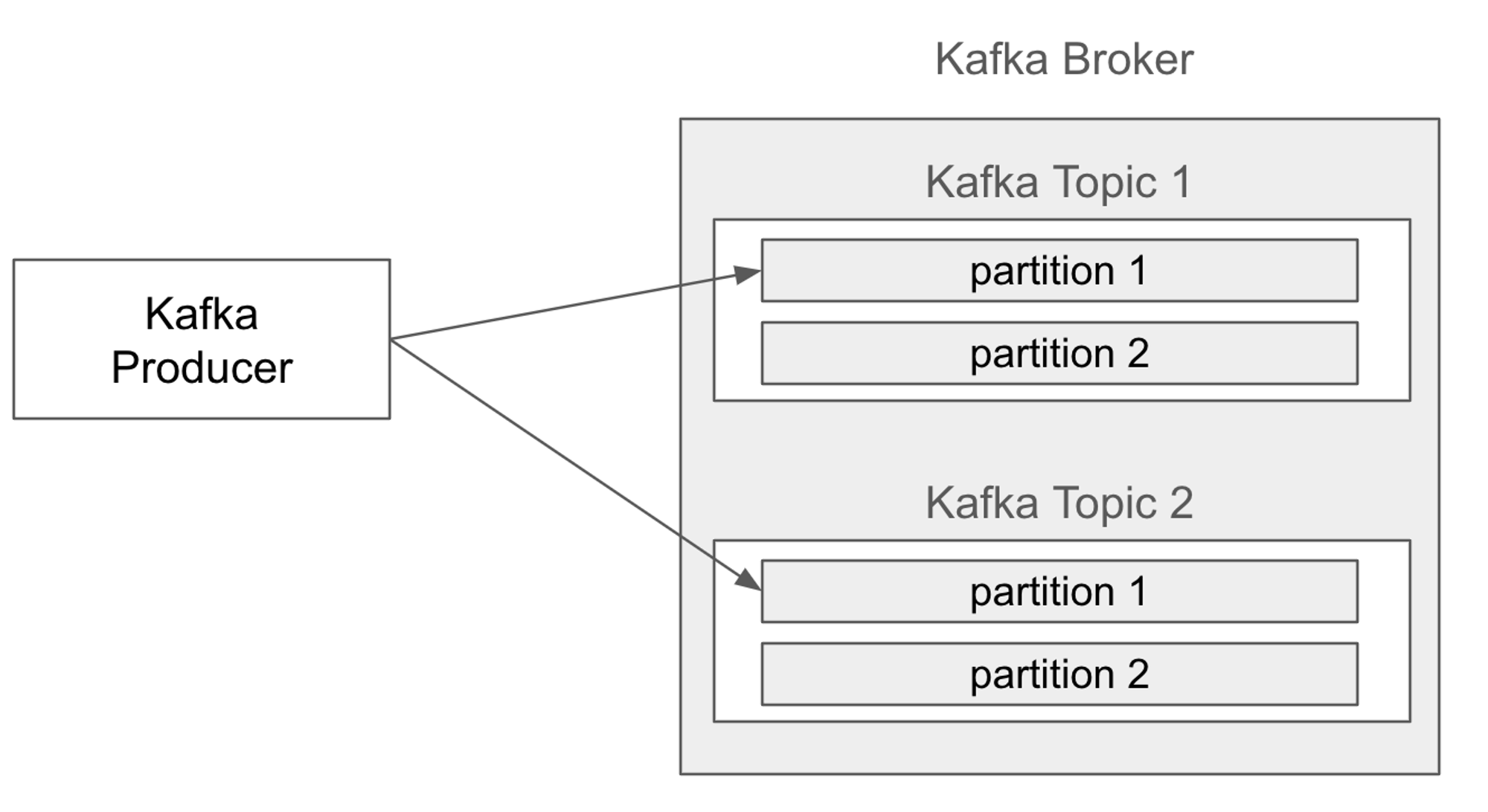
토픽은 Consumer Group과 대응되며, 토픽에 파티션에 발행된 메시지는 Consumer Group에 속한 Consumer에게 할당된다. 따라서 병렬 처리의 효율성을 가장 잘 발휘하려면 파티션 수와 컨슈머 그룹에 속한 컨슈머의 수를 1:1로 맞추는 것이 좋다.
- 파티션 개수 > 컨슈머 수 : 어떤 컨슈머는 다른 컨슈머보다 많은 메시지를 처리해야한다.
- 파티션 개수 < 컨슈머 수 : 어떤 컨슈머는 메시지를 처리하지 않고 놀게된다. (유휴 상태로 리소스 낭비)
동일한 토픽에 대해 다른 방식으로 처리하기 위해선 (일반적으로) 별도의 컨슈머 그룹을 추가한다. 이를 통해 각 그룹은 독립적으로 메시지를 처리할 수 있고, 동일한 메시지에 대해 용도와 서비스 목적에 맞게 다양한 방식으로 처리할 수 있다.(로깅 데이터를 받아와서 RDB 적재, NoSQL 적재, 검색엔진 적재 등 다양하게 처리할 수 있다.)
Spring Kafka를 사용한다면 다음 이미지의 빨간 화살표대로 데이터를 Consuming한다.
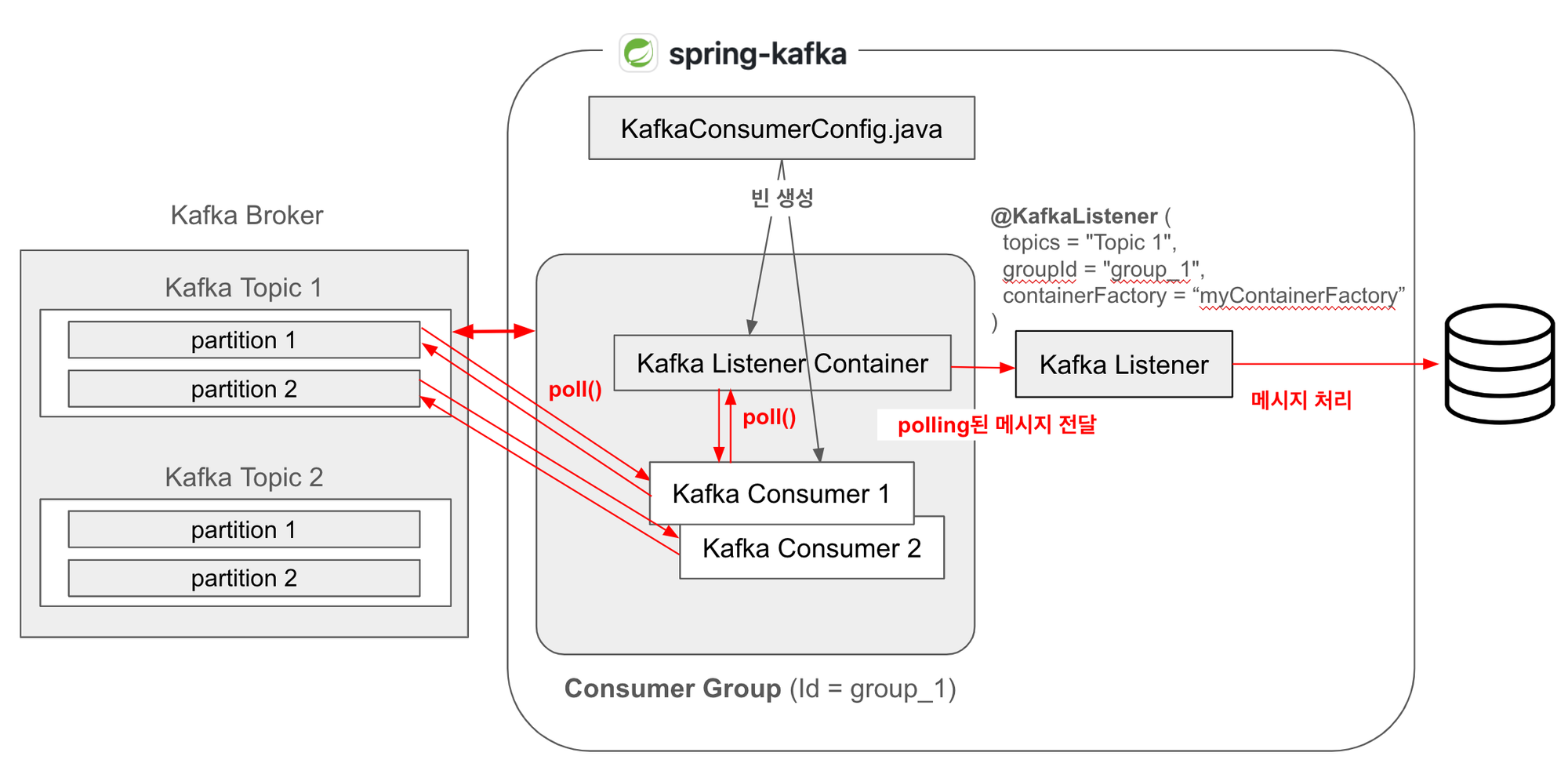
흐름을 정리해보면 다음과 같다.
- Producer가 메시지를 발행한다.
- Kafka Broker가 메시지를 저장한다.
- Kafka Consumer가 메시지를 소비하고, 컨슈머 그룹 내의 컨슈머가 파티션을 할당받아 처리한다.
- KafkaConsumer 인스턴스가 직접 Kafka 브로커와 연결되어 있다.
- KafkaConsumer는 (KafkaListenerContainer에 의해) 주기적으로 poll() 메서드를 호출하여 브로커로부터 메시지를 요청한다.
- 브로커는 KafkaConsumer의 요청에 따라 메시지를 반환하고 이 메시지는 KafkaConsumer의 내부 큐에 저장된다.
- KafkaListenerContainer가 내부적으로 KafkaConsumer의 poll() 메서드를 호출하여 메시지를 폴링한다.
- 이 poll() 메서드를 주기적으로 호출하여 KafkaConsumer의 poll()을 호출하는 것이다.
- 폴링된 메시지가 있다면 @KafkaListener 어노테이션이 붙은 메서드에게 전달한다.
- KafkaListener가 메시지를 처리하고, (로직에 따라서) 최종적으로 DB에 적재된다.
테스트
카프카 Consumer 설정까지 마치고 나면, Consumer에 쿠폰 발급 로직 추가하고 테스트를 진행해보자.
Coupon
데이터베이스의 Coupon 테이블에 매칭될 엔티티 클래스이다.
package org.example.consumer.domain;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import lombok.Getter;
import lombok.NoArgsConstructor;
// Database의 Coupon 테이블과 매칭될 엔티티 클래스
@Entity
@NoArgsConstructor
public class Coupon {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id; // coupon id
@Getter
private Long userId; // 쿠폰을 발급받은 사용자의 id
public Coupon(Long userId) {
this.userId = userId;
}
}
CouponRepository
DB에 접근하여 쿠폰 엔티티에 대한 CRUD를 수행한다.
package org.example.consumer.repository;
import org.example.consumer.domain.Coupon;
import org.springframework.data.jpa.repository.JpaRepository;
// 쿠폰 엔티티(Coupon)에 대한 CRUD를 제공
public interface CouponRepository extends JpaRepository<Coupon, Long> {
}
CouponCreatedConsumer 수정
CouponRepository와의 의존관계를 주입하고, CouponRepository를 통해 쿠폰을 발급하는 로직을 추가한다.
package org.example.consumer.consumer;
import org.example.consumer.domain.Coupon;
import org.example.consumer.repository.CouponRepository;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class CouponCreatedConsumer {
private final CouponRepository couponRepository;
public CouponCreatedConsumer(CouponRepository couponRepository) {
this.couponRepository = couponRepository;
}
@KafkaListener(
topics = "coupon-create", // 토픽 명 지정
groupId = "group_1" // 컨슈머 그룹 ID 지정
containerFactory = "kafkaListenerContainerFactory" // Listner Container Factory 지정
)
public void listener(Long userId) {
couponRepository.save(new Coupon(userId));
}
}
테스트 코드 실행
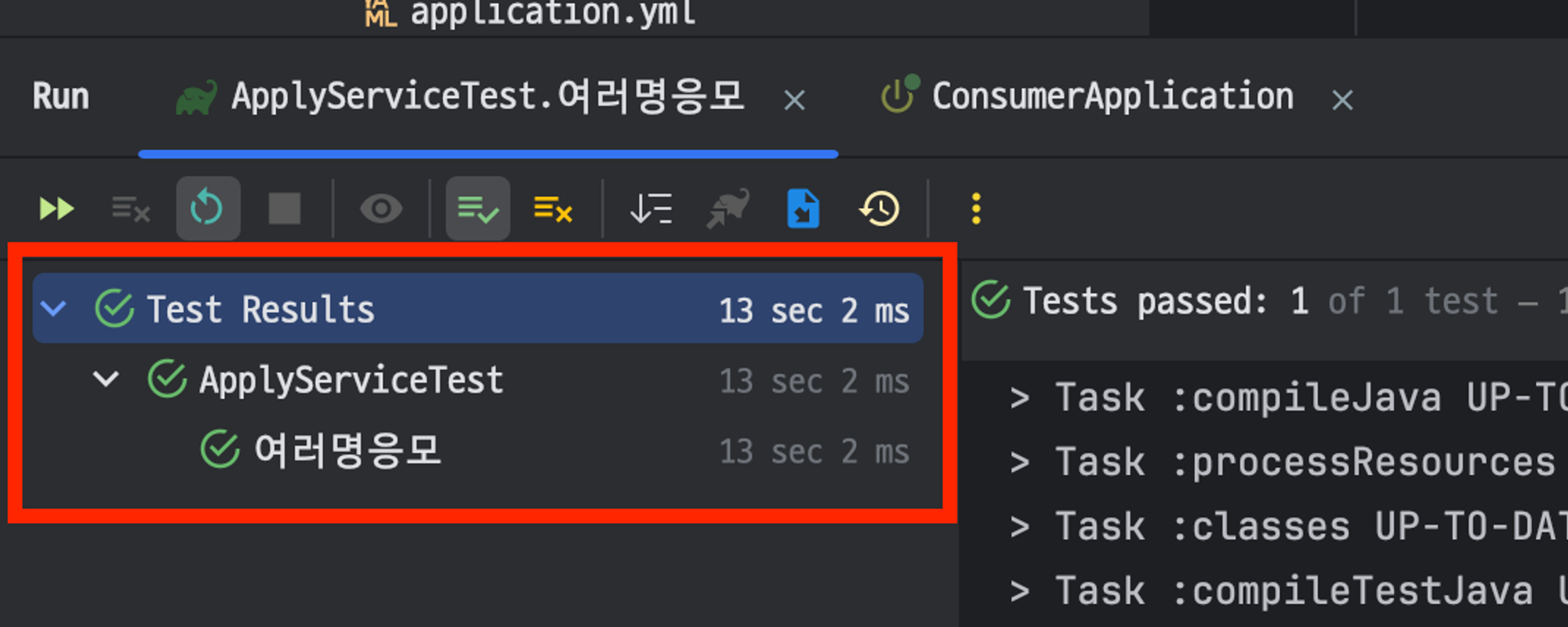
Consumer에서 쿠폰 발급에 필요한 로직을 작성하고 나서 테스트 코드 ApplyServiceTest.여러명응모() 를 실행해본다.
Consumer에서 insert 쿼리를 호출하여 Coupon을 발급하는 것을 확인할 수 있다.
하지만 100개의 쿠폰 발급을 예상했으나 10개만 발급되어 테스트는 실패한다.
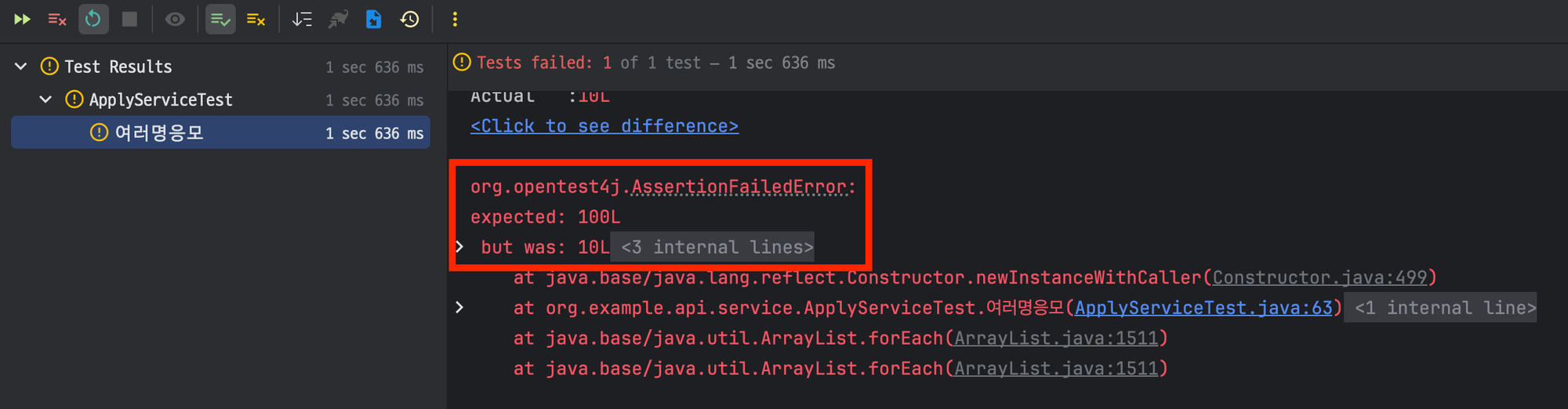
이는 Consumer의 테스트 데이터가 실시간으로 처리되지 않았기 때문이다.
테스트 케이스는 메시지 발행만 완료하면 테스트를 종료한다. 하지만 테스트를 종료하는 시점에 컨슈머는 메시지를 처리하고 있고 아직 프로듀서가 발행한 메시지를 모두 처리하지 않았으므로(테이블에 적재가 안되었으므로) 테스트는 실패한다.

즉 테스트 코드의 종료 시점과 데이터베이스에 쿠폰 적재 시점간의 차이로 인해 테스트가 실패한 것이다. 이를 해결하기 위해서 테스트 코드에서 메시지를 발행하고 나서 일시적으로 스레드를 중지한다.
@Test
public void 여러명응모() throws InterruptedException {
int threadCount = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount); // count 값을 threadCount 값으로 초기화
for(int i = 0; i < threadCount; i++) {
long userId = i;
executorService.execute(() -> {
try {
applyService.apply(userId);
} finally {
// count 값을 1 감소
latch.countDown();
}
});
}
// await() 이후 로직은 count 값이 0이 되고 나서 실행된다.
latch.await();
// 컨슈머가 메시지를 처리하는 동안 잠시 대기
Thread.sleep(10000);
// 100개의 쿠폰이 생성된 것을 예상
long count = couponRepository.count();
assertThat(count).isEqualTo(100);
}
테스트가 성공적으로 수행되는 것을 볼 수 있다.
부하 테스트
앞서 [시스템 디자인] 실습으로 배우는 선착순 이벤트 시스템 (1/3) - 동시성 이슈와 Redis로 해결하기 진행했던 부하테스트도 다시 진행하여 시스템 안정성이 향상되었는지 확인해본다.
기존에 작성한 스크립트를 그대로 사용한다. 초당 5000명의 user가 10초간 요청을 보내는 상황을 가정하고 있다.
import http from 'k6/http';
import { check, sleep } from 'k6';
// 초당 1000명의 user가 30초간 요청을 보내는 상황을 가정
export const options = {
// A number specifying the number of VUs to run concurrently.
vus: 5000,
// A string specifying the total duration of the test run.
duration: '10s',
};
export default function() {
// 요청 본문 데이터
const userId = __VU; // __VU : 현재 가상 사용자 ID
const payload = JSON.stringify({
userId: userId.toString(),
});
// POST 요청 헤더
const headers = {
'Content-Type': 'application/json',
};
// POST 요청
const response = http.post('http://localhost:8080/coupon/apply', payload, {headers});
// 응답 검증
check(response, {
"is OK": (response) => response.status === 200,
});
}
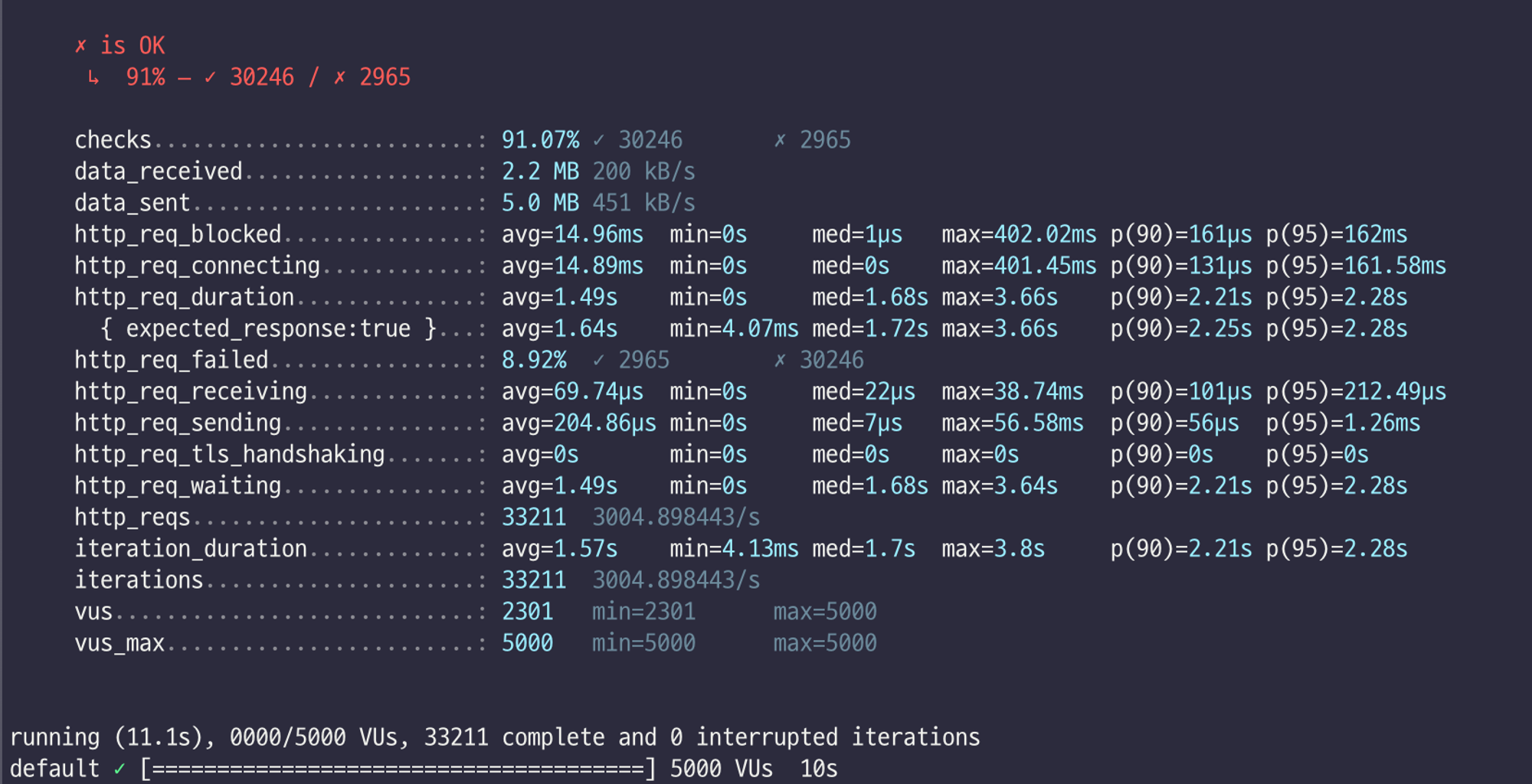
부하테스트 진행 결과 초당 트랜잭션 처리 건수는 3004.90 tps, 요청 성공율이 91% 로 향상된 것을 볼 수 있다.
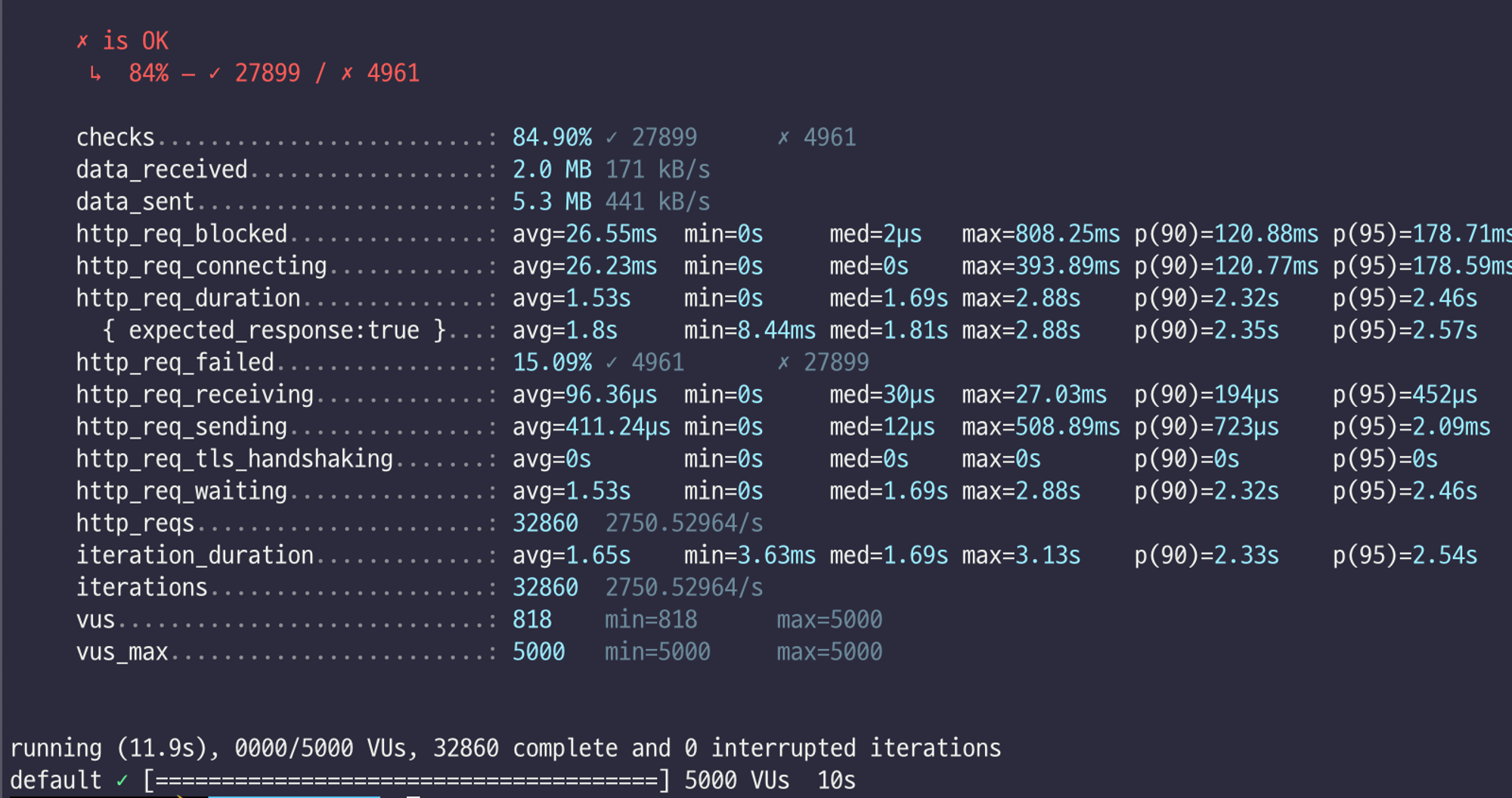
참고로 이전에 DB에 직접 요청하는 경우는 측정 결과는 다음과 같다. 초당 트랜잭션 처리 건수는 2750.53 tps, 요청 성공율은 84%였다.
정리
데이터베이스에 직접 적재하지 않고 카프카를 도입했을때 초당 트랜잭션 처리 건수가 2750.53 tps →. 3004.90 tps, 요청 성공율이 84% → 91% 로 향상된 것을 볼 수 있다. 즉, 카프카가 시스템의 안정성을 높이는데 유효했다.
반면 위 부하테스트 결과를 보면 평균 응답 속도와 최대 응답속도, p90(전체 요청 중 상위 90% 응답 속도), p95(전체 요청 중 상위 95% 응답 속도)는 큰 개선이 없었다. 사실 이 상황에서 카프카 도입의 주요 목표는 응답 시간 향상보다는 시스템의 안정성과 부하 처리 능력 향상에 있다. 만일 응답 속도 향상과 측정도 필요하다면 토픽 파티셔닝과 적절한 컨슈머의 수를 측정하고 구성하는 것이 필요할 것이다.
결국 처리 속도가 향상되지는 않았지만 시스템 안정성을 높이고 대규모 요청에 대해 부하 처리 능력 향상에 기여했다.
예를 들어 DB에 부하를 주게되면 다른 서비스(e.g. 주문, 회원가입 등)에 영향을 주거나 타임아웃 정책에 따라 일부 쿠폰 생성 요청도 처리되지 않을 것이다. 그리고 이는 서비스 지연 혹은 오류로 이어질 것이다. 하지만 카프카에 메시지를 발행하는 경우 DB 부하가 적은 시간에 데이터베이스에 쿠폰 발행을 진행하거나 처리량을 유연하게 조절하여 대처할 수 있다. 결국 안정성과 부하 처리 능력을 향상하였다.
데이터베이스에 직접 접근하는 방식은 카프카에 메시지를 발행하는 것보다 더 빠른 응답 시간을 제공할 수 있지만 부하가 증가할 경우 시스템 안정성이 저하되고 카프카보다 실패율이 높아질 수 있다. 따라서, 대규모 트래픽 처리와 안정성이 중요한 상황에서 높은 안정성과 낮은 실패율이 요구되는 경우 카프카를 도입하는 것이 의미가 있다는 것을 확인하였다.
또한 테스트 케이스에서 확인했듯이 쿠폰 발급까지 약간의 텀이 존재하여 테스트가 어렵다는 단점이 존재한다. 실무에서는 카프카를 사용하는 경우 다른 팀과 함께 테스트를 진행하는 경우가 있는데, 그만큼 기술적인 숙련도와 업무적인 소프트 스킬이 요구된다.



