[시스템 디자인] 재고시스템으로 알아보는 동시성이슈 해결방법 (1/3) - 동시성 이슈와 Application Level로 해결하기
💡 최상용님의 재고시스템으로 알아보는 동시성이슈 해결방법 강의를 듣고 정리한 내용입니다.
목차
글 목록
- [시스템 디자인] 재고시스템으로 알아보는 동시성이슈 해결방법 (1/3) - 동시성 이슈와 Application Level로 해결하기
- [시스템 디자인] 재고시스템으로 알아보는 동시성이슈 해결방법 (2/3) - 데이터베이스 락(Lock)으로 해결하기
- [시스템 디자인] 재고시스템으로 알아보는 동시성이슈 해결방법 (3/3) - 레디스 분산 락(Lock)으로 해결하기
배경
과거 애플리케이션 실행 속도가 너무 느려 해결방안을 고민하던 도중 멀티 스레드 환경에서 처리할 수는 없을까 의문을 가졌던 적이 있다. 하지만 당시에는 멀티 스레드 환경으로 개발할 때 발생하는 이슈와 주의해야할 점, 이슈 해결 방안에 대해 충분한 지식이 없었고, 그런 상황에서 실무에 도입하기에는 무리가 있을 것이라 생각했다.
이 일을 계기로 멀티 스레드 환경에서 개발할때 고려해야할 점, 발생해야하는 이슈, 대응 방안 등에 대한 관심을 갖던 도중 인프런의 재고시스템으로 알아보는 동시성이슈 해결방법이라는 강의를 추천받아 수강하였다. 개인적으로 강의 내용은 매우 만족스러웠고, 학습한 내용을 개인 깃 허브와 노션 페이지에도 기록해두었으나 내가 원래 갖고 있던 지식과 결합하여 온전히 내 지식으로 만들기위해 글로 다시 한 번 정리하였다.
강의 소개
어떤 작업을 처리하는데 속도가 너무 오래걸려 서비스에 영향을 주는 경우, 로직 처리를 위해 애플리케이션 응답속도와 처리량 향상을 위해 멀티 스레드(Multi-thread) 환경을 고려할 수 있다. 하지만 멀티 스레드 환경에서 여러 개의 작업 스레드가 동시에 작업을 처리하기 위해 동일한 데이터에 접근하고 변경하게 되면, 데이터 일관성이 깨지거나 레이스 컨디션(Race Condition)과 같은 문제가 발생하여 의도한 대로 작업이 처리되지 않을 수 있다.
강의에서는 상품 재고를 관리하는 간단한 재고 시스템을 구현하여 멀티 스레드 환경에서 발생하는 동시성 문제를 마주하고 발생 원인을 분석한다. 해결 방안으로는 3가지 방법을 차례대로 적용하여 해결해본다. 첫번째 방법은 Application level에서 자바의 synchronized 키워드를 사용하여 해결하는 것이고, 두번째는 Database가 제공하는 Lock, 마지막으로 세번째는 레디스(Redis)로 분산 락(Distributed lock)을 구현하여 해결하는 것이다.
동시성 문제는 실무에서 발생할 수 있을 뿐만 아니라 최근에는 기술 면접, 과제 전형에서도 요구한다. 따라서 평소 멀티 스레드 환경에서 어떠한 동시성 문제가 발생할 수 있다는것을 인지하고 스레드 안전성을 제공할 수 있는 해결 방법을 알아두는 것이 중요하다. 이번 글에서는 멀티 스레드 환경에서 개발할때 발생하는 문제점과 발생 원인을 살펴보고 먼저 Application level에서 자바의 synchronized 키워드를 사용하여 해결해볼 것이다.
작업 환경 세팅
재고 시스템을 구현하기 위한 프로젝트 환경 세팅을 위해서는 Java, Spring Boot, Spring Data JPA, Docker, Mysql, Redis를 사용하였다. 각각의 버전은 다음과 같다.
- 스프링 부트 : 3.3.2
- 자바 : 17
- 의존성 : Spring Web, MySQL Driver, Spring Data Jpa
재고감소 로직 작성
간단한 재고 관리 시스템을 구현한다. 먼저 재고 감소 로직을 작성한다.
Stock
데이터베이스의 재고 정보를 담고있는 테이블과 매칭될 재고 도메인 클래스이다. @Entity 어노테이션을 추가하여 동일한 이름의 테이블과 매칭한다. PK로는 id를 둔다. PK 값은 데이터베이스의 auto increment 전략을 따른다.
package com.example.stock.domain;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
@Entity // DB의 테이블로 매핑
public class Stock {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
public Stock() {
}
public Stock(Long id, Long quantity) {
this.id = id;
this.quantity = quantity;
}
public Long getQuantity() {
return quantity;
}
public void decrease(Long quantity){
if(this.quantity - quantity < 0){
throw new RuntimeException("재고는 0개 미만이 될 수 없습니다.");
}
// 현재 수량을 갱신
this.quantity -= quantity;
}
}
StockRepository
재고(StocK) 테이블에 대한 간단한 CRUD 기능을 제공한다. Spring Data JPA를 사용한다.
package com.example.stock.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.example.stock.domain.Stock;
// StockRepository : 재고(Stock)에 대한 데이터베이스와의 CRUD 기능 제공
public interface StockRepository extends JpaRepository<Stock, Long> {
}
StockService
StockRepository에 의존하여 재고에 대한 CRUD 기능을 활용한 비즈니스 로직을 제공한다.
재고 감소 로직인 decrease() 메서드를 구현한다.
package com.example.stock.service;
import java.util.Optional;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import com.example.stock.domain.Stock;
import com.example.stock.repository.StockRepository;
@Service
public class StockService {
private final StockRepository stockRepository;
public StockService(StockRepository stockRepository) {
this.stockRepository = stockRepository;
}
// 재고 감소 로직 구현
@Transactional
public void decrease(Long id, Long quantity) {
// Stock 조회
Optional<Stock> stock = stockRepository.findById(id);
// 재고 감소
stock.orElseThrow(() -> new RuntimeException("해당하는 재고가 없습니다."))
.decrease(quantity);
// 갱신된 값을 저장
stockRepository.save(stock.get());
}
}
StockServiceTest
StockService의 재고 감소 로직인 decrease() 메서드를 테스트한다.
package com.example.stock.service;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import com.example.stock.domain.Stock;
import com.example.stock.repository.StockRepository;
@SpringBootTest
class StockServiceTest {
@Autowired
private StockService stockService;
@Autowired
private StockRepository stockRepository;
// 각 테스트가 실행되기 전에 데이터베이스에 테스트 데이터 생성
@BeforeEach
public void before() {
stockRepository.saveAndFlush(new Stock(1L, 100L));
}
// 각 테스트를 실행한 후에 데이터베이스에 테스트 데이터 삭제
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void 재고감소() {
// when
stockService.decrease(1L, 1L);
// then : 1L 상품의 재고 : 100 - 1 = 99개가 남아있어야함
Stock stock = stockRepository.findById(1L).orElseThrow();
assertEquals(99, stock.getQuantity());
}
}
재고 감소 로직 테스트
먼저 하나의 스레드가 재고 감소 로직을 호출하는 경우를 테스트한다. 테스트가 성공하는 것을 볼 수 있다.
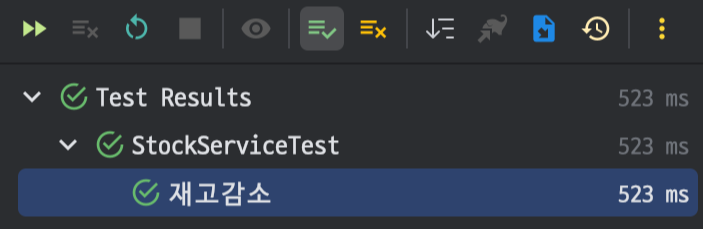
다음으로는 100개의 스레드가 동시에 재고 감소 로직을 호출하는 경우를 테스트한다.
@Test
public void 동시에_100개의_요청() throws InterruptedException {
// when
// 100개의 쓰레드 사용(멀티스레드)
int threadCount = 100;
// ExecutorService : 비동기로 실행하는 작업을 간단하게 실행할 수 있도록 자바에서 제공하는 API
ExecutorService executorService = Executors.newFixedThreadPool(32);
// CountDownLatch : 작업을 진행중인 다른 스레드가 작업을 완료할때까지 대기할 수 있도록 도와주는 클래스
CountDownLatch latch = new CountDownLatch(threadCount);
// 100개의 작업 요청
for(int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
} finally {
// CountDownLatch 1 감소
latch.countDown();
}
});
}
// CountDownLatch이 0이 될때까지 스레드 대기 - await() 이후 로직은 CountDownLatch이 0이 되고나서 수행된다.
latch.await();
// then
Stock stock = stockRepository.findById(1L).orElseThrow();
assertEquals(0, stock.getQuantity());
}
재고 수량을 100개로 세팅하고하고 100개의 스레드가 한 번씩 재고 감소 로직을 호출하기때문에 최종적으로 0개의 수량이 남게 될 것을 예상했다.
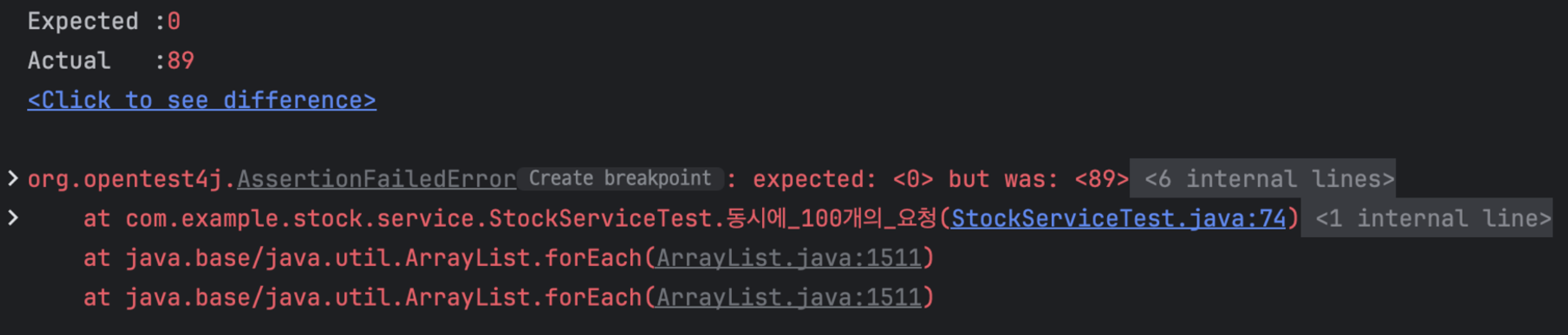
하지만 최종적으로 89개의 재고 수량이 남고 테스트는 실패한다.
발생 원인
이는 두개 이상의 스레드가 재고(Stock)라는 공유 데이터에 동시에 접근하고 변경하면서 경합 상태(Race Condition)이 발생했기 때문이다. 다음과 같이 순차적으로 재고의 수량(quantity)를 업데이트할 것을 예상하였다.
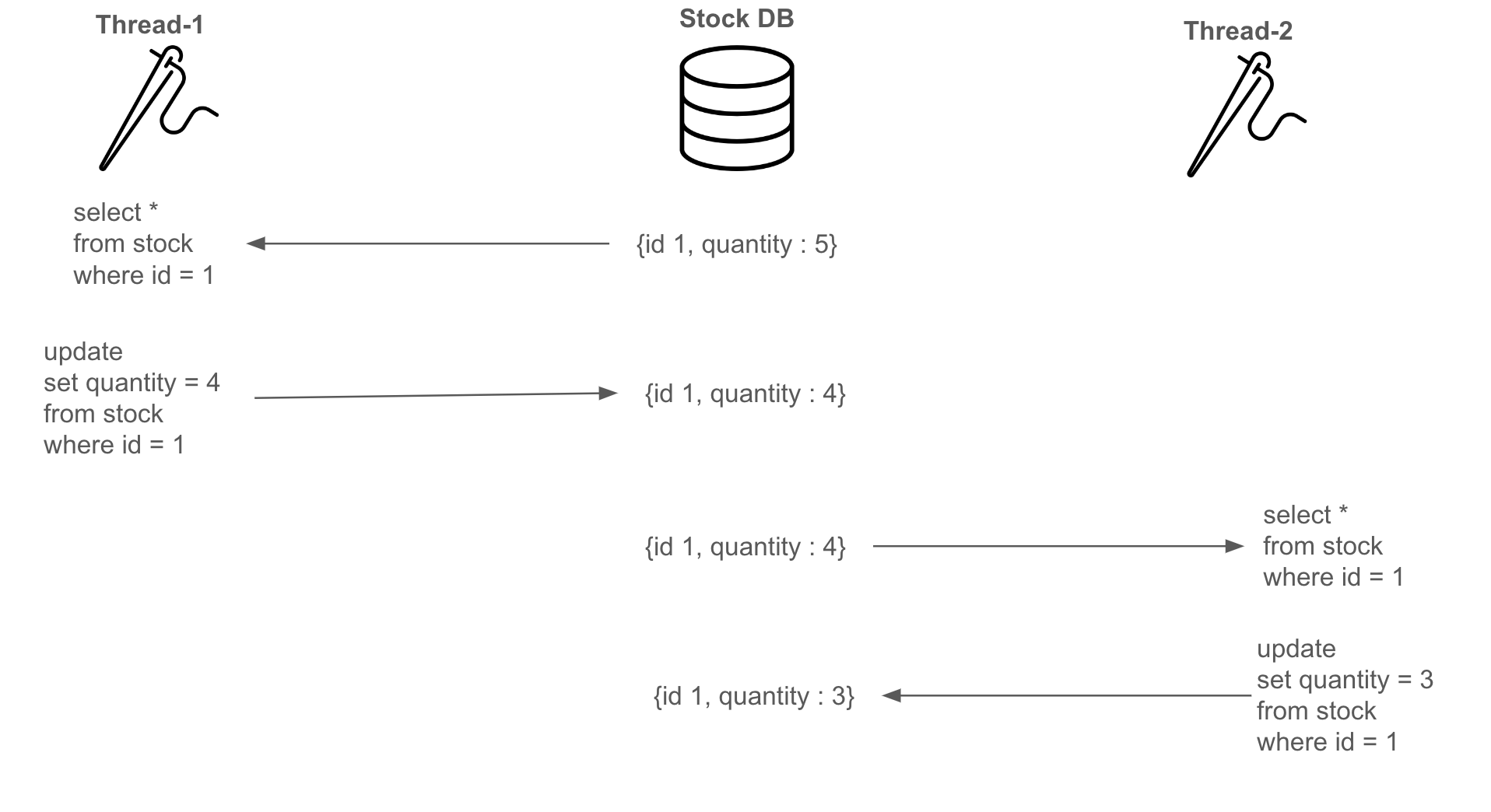
하지만 실제로는 Thread-1이 재고 수량을 조회(e.g. quantity = 5)하고 1만큼 감소하고나서 DB에 반영하기 전에 Thread-2가 동일한 수량의 재고를 조회하고 1만큼 감소한다.
이때 Thread-1이 1만큼 감소한 재고 수량(e.g. quantity = 4)을 DB에 반영하고 Thread-2도 1만큼 감소한 값으로 갱신하면 Thread-1이 작업하고 반영한 결과는 사라진다. (이를 Lost update라 한다.)
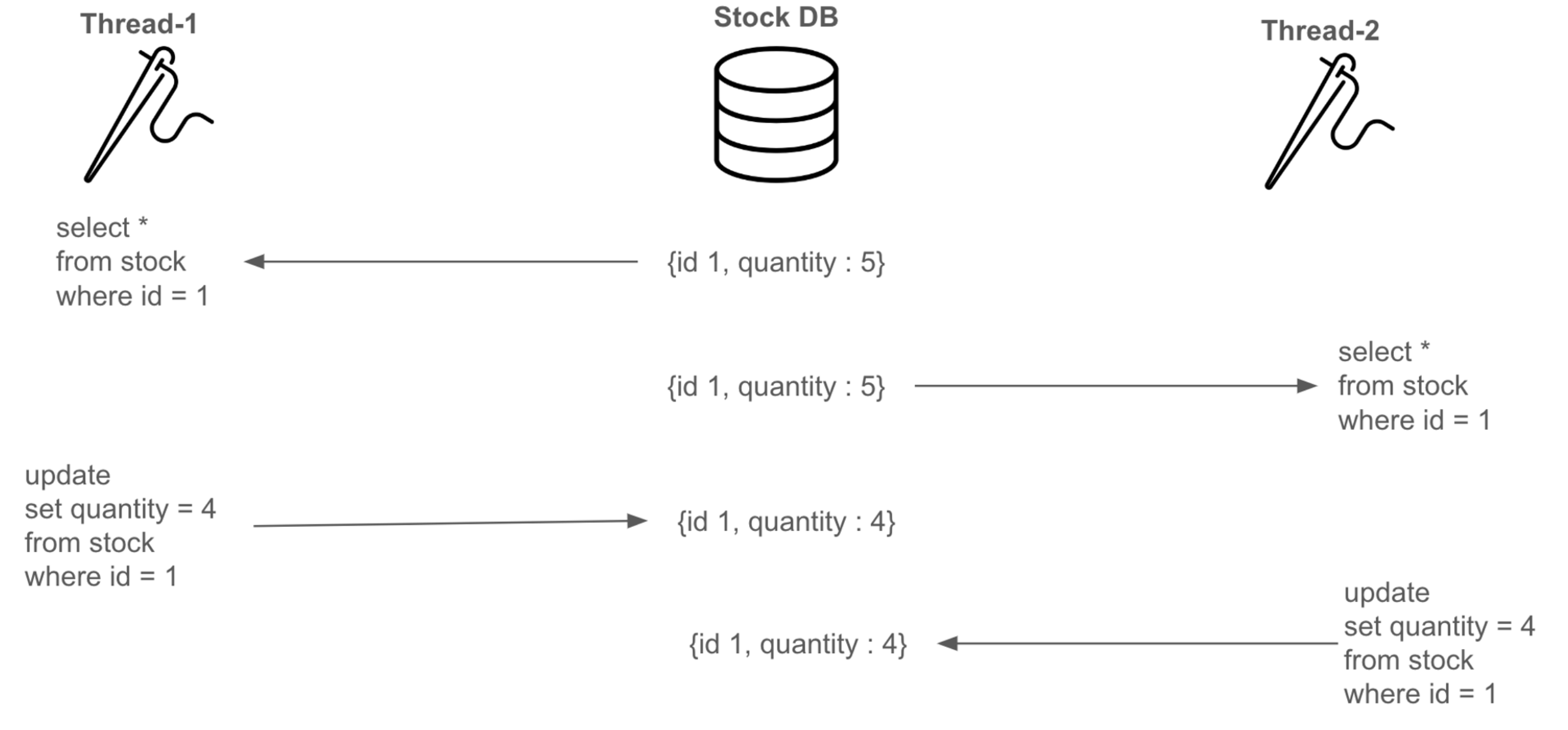
결국 두 개 이상의 스레드가 id = 1인 Stock이라는 공유 데이터에 엑세스하여 동시에 변경하면서 경합 상태(Race condition)이 발생한 것이다. 이를 해결하기 위해서는 하나의 쓰레드가 작업이 완료된 이후에 다른 쓰레드가 데이터에 접근할 수 있도록 제어를 해야한다.
Application Level에서 해결
먼저 Application Level에서 동시성 이슈인 경합 상태를 해결한다. 자바에서 제공하는 Synchronized 키워드로 문제를 해결해본다.
Synchronized
한 개의 쓰레드만 접근이 가능하도록 자바에서 제공하는 키워드이다. 메서드 선언부에 다음과 같이 Synchronized 키워드를 추가하면 한 개의 쓰레드만 메서드에 접근이 가능해진다.
package com.example.stock.service;
import java.util.Optional;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import com.example.stock.domain.Stock;
import com.example.stock.repository.StockRepository;
@Service
public class StockService {
private final StockRepository stockRepository;
public StockService(StockRepository stockRepository) {
this.stockRepository = stockRepository;
}
// 재고 감소 로직 구현
@Transactional
public synchronized void decrease(Long id, Long quantity) {
// Stock 조회
Optional<Stock> stock = stockRepository.findById(id);
// 재고 감소
stock.orElseThrow(() -> new RuntimeException("해당하는 재고가 없습니다."))
.decrease(quantity);
// 갱신된 값을 저장
stockRepository.save(stock.get());
}
}
StockServiceTest에 작성했던 동시에_100개의_요청()를 호출하여 테스트를 다시 실행해본다.
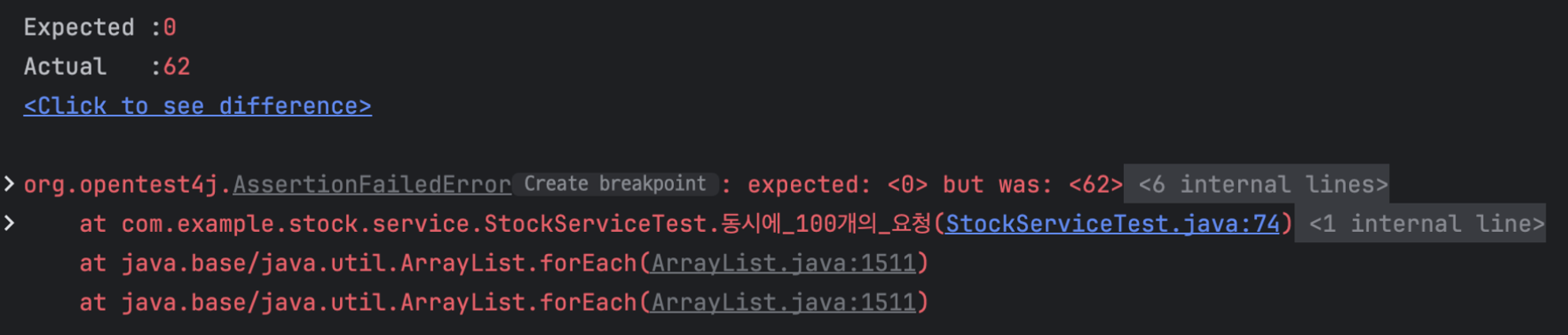
테스트가 성공할 줄 알았으나 여전히 테스트가 실패하는 것을 볼 수 있다.
실패 원인
이는 StockService의 decrease() 메서드에 추가한 스프링의 @Transactional 어노테이션의 동작 방식 때문이다. 스프링의 @Transactional 어노테이션을 메서드 혹은 클래스 레벨에 추가하면, 스프링은 해당 클래스가 아닌 해당 클래스를 감싸고 있는 proxy 객체를 빈으로 등록하고 위존관계 주입에 사용한다.
즉, 다음과 같이 StockService를 감싸고 있는 TransactionStockService 클래스를 스프링이 빈으로 등록하는 것이다. 스프링의 @Transactional 어노테이션은 아래 코드와 같이 트랜잭션을 시작하고 타겟 클래스를 호출하고나서 로직이 완료되면 변경사항을 커밋(혹은 롤백)하고 트랜잭션을 종료하는 방식으로 동작한다.
package com.example.stock.service;
public class TransactionStockService {
private StockService stockService;
public TransactionStockService(StockService stockService) {
this.stockService = stockService;
}
public void decrease(Long id, Long quantity) {
// 트랜잭션 시작
startTransaction();
// 타겟 클래스 호출
stockService.decrease(id, quantity);
// 트랜잭션 종료
endTransaction();
}
private void startTransaction() {
System.out.println("Transaction started");
}
private void endTransaction() {
System.out.println("Commit");
}
}
그림으로 나타내면 다음과 같다.
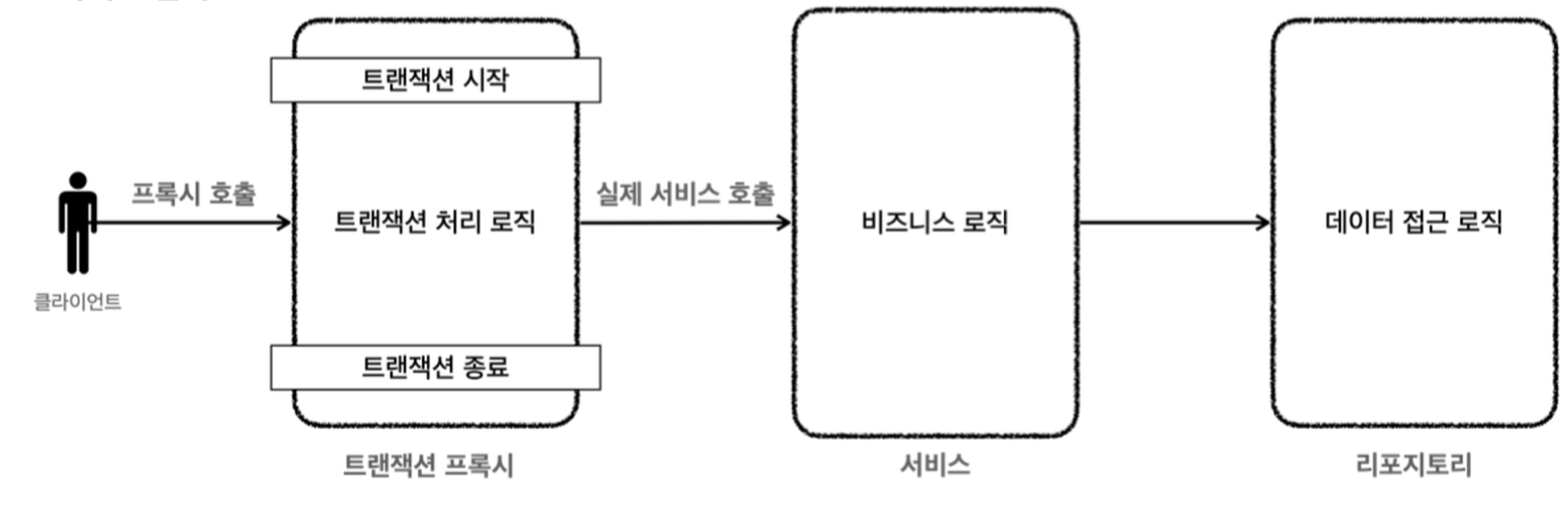
하지만 이러한 @Transactional 어노테이션의 동작 방식 때문에 의도와 다르게 동작한다. decrease() 메서드에 @Transactional 어노테이션을 두게되면 StockRepository의 save() 메서드를 호출하는 시점에 갱신된 값이 DB에 반영(커밋)하는 것이 아니라 StockService의 모든 로직을 수행하고 나서 StockService의 proxy 객체가 변경사항을 반영(커밋)한다.
다시 말해 StockService의 decrease 메서드는 한 번에 한 스레드만 접근하기 위해 synchronized 키워드를 두었어도, proxy 객체가 변경사항을 반영(커밋)하기 전에 다른 스레드에서 재고 수량을 조회하면 이전의 재고 수량을 조회하게되고 결국 여전히 경합 상태가 발생하는 것이다.
물론 @Transactional 어노테이션을 해제하고 실행하면 테스트 케이스가 성공하는 것을 볼 수 있다.
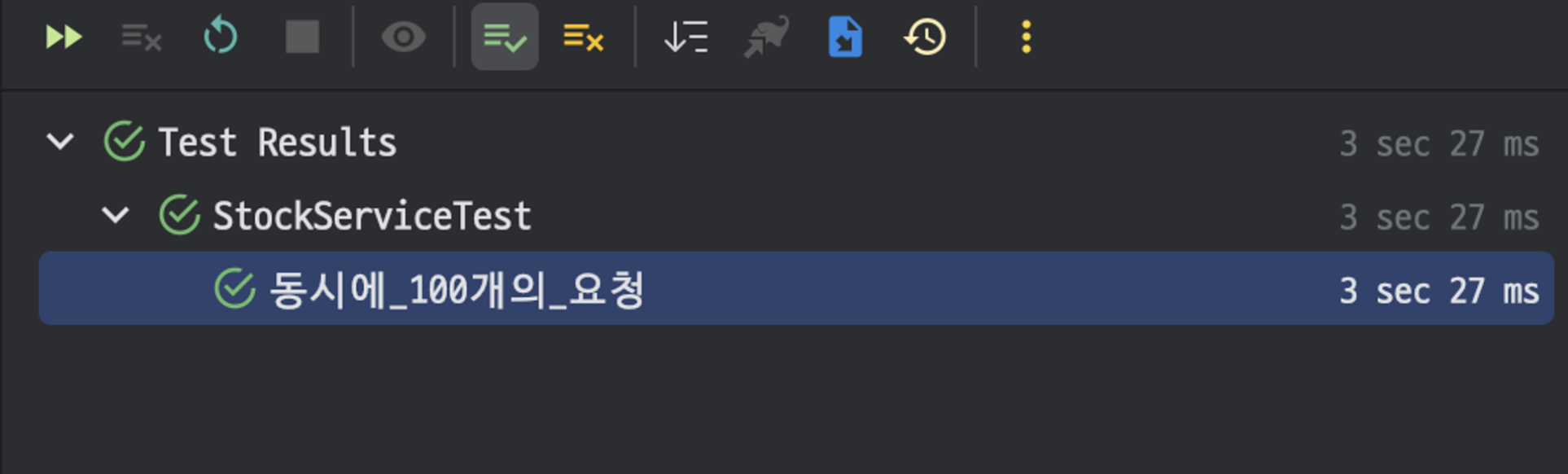
문제점
그렇다고 동시성 이슈를 해결하기 위해 @Transactional 어노테이션을 사용하지 말고 synchronized 키워드를 두어야할까?
스프링의 @Transactional 어노테이션은 데이터 관리 관점에서 굉장한 편의성을 개발자에게 제공한다. 만일 이 어노테이션을 사용하지 않는다면 개발자는 비즈니스 로직을 작성할때마다 매번 DB 커넥션을 조회하고 커밋하거나 롤백하는 로직을 작성해주어야할 것이다. 또한 스프링의 트랜잭션 매니저는 다양한 데이터 접근 기술에 대한 추상화된 트랜잭션 관리 방안을 제공하는데 이러한 이점도 얻을 수 없다.
또한 스프링의 @Transactional 어노테이션은 체크 예외와 언체크 예외(런타임 예외) 별로 다르게 동작하며 안정적인 프로그램 개발에도 많은 기여를 한다.
예컨대 예상치못한 런타임 예외(e.g. NullPointerException, IllegalArgumentException)가 발생하면 트랜잭션을 롤백하여 변경사항을 DB에 반영하지 않는다. 반면 비즈니스 예외상 의도적으로 던지는 예외를 구현하는데 주로 쓰이는 체크 예외가 발생하면 트랜잭션을 커밋하여 진행 상태를 DB에 반영하는 식이다. (물론 @Transactional의 rollbackFor 속성을 사용하여 특정 체크 예외에 대해서도 롤백을 지정할 수 있다.)
만일 @Transactional 어노테이션을 사용하지 않는다면 이처럼 예외 계층 별로 적절한 처리 방안을 개발자가 모두 작성해주어야할 것이다.
이 외에도 자바의 Synchronized 키워드가 제공하는 동기화 작업은 하나의 프로세스 안에서만 보장이 된다는 치명적인 단점이 있다.
즉 한 대의 서버에서 멀티쓰레드로 작업하는 경우에는, 공유 자원에 대한 접근은 한 대의 서버안에서만 이루어지기 때문에 안전한 접근을 보장한다.하지만 서버가 여러대인 경우 여러 서버에서 공유 자원에 접근할 수 있으므로 쓰레드 안전성이 보장이 되지 않는다.
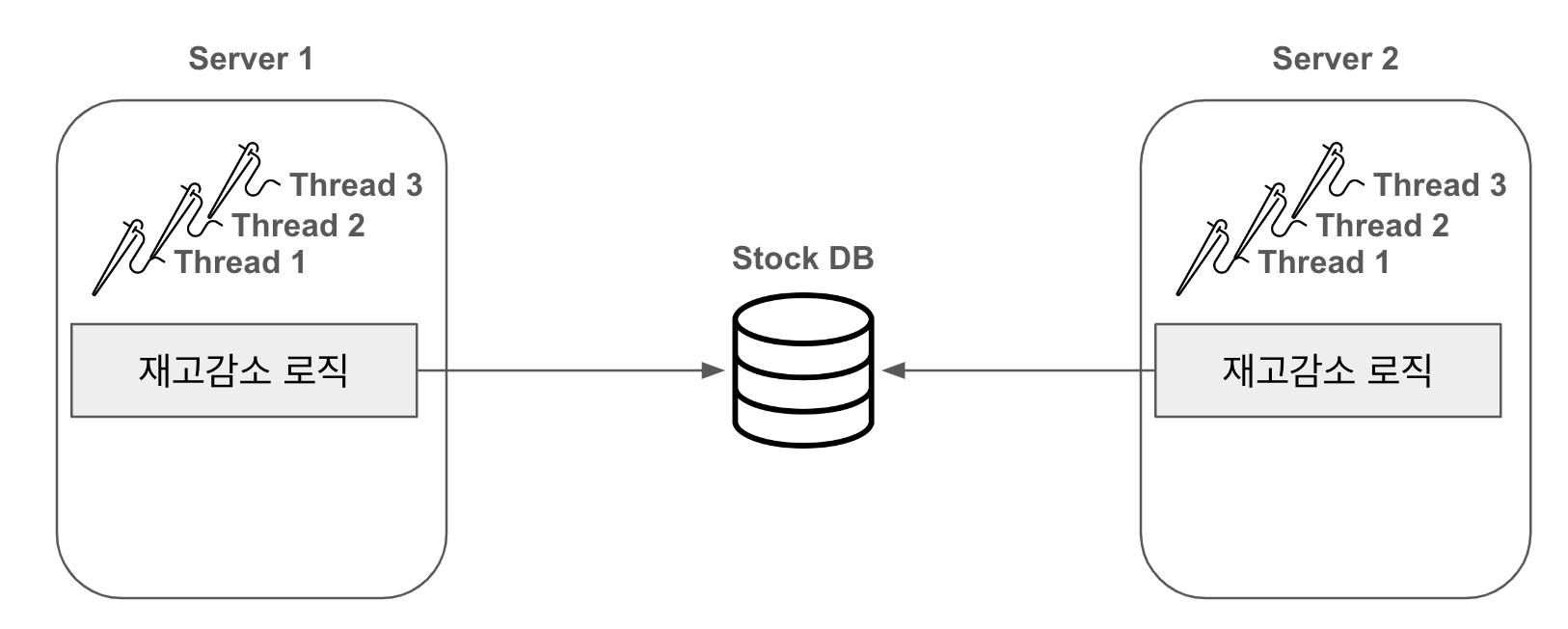
실무에서 일반적으로(간단한 시스템일지라도) 운영 서버는 보통 한 대만 두지 않는다. 여러 대의 장비와 서버 인스턴스를 두는데 결국 여러대의 서버가 동시에 공유 자원에 접근하게되면 결국 여전히 Race Condition이 발생하는 것이다. 따라서 실무에서 Synchronized 거의 사용하지 않는다.
결국 동시성 이슈를 해결하려면 별도의 동기화 메커니즘이 필요하다. 다음 글에서는 데이터베이스에서 제공하는 Lock을 활용하여 문제를 해결해본다.